Using String Handling Functions in Pandas for Sales Data Analysis
PANDAS
Kishore Babu Valluri
5/15/20254 min read


In the fast-paced world of sales, data often comes in various formats—customer names, product codes, regions, emails, and more. Cleaning and transforming this data is crucial for accurate reporting and insights.
In this post, we'll explore how to use string handling functions in Python (with Pandas) to process real-world sales data.
📦 Sample Sales Dataset
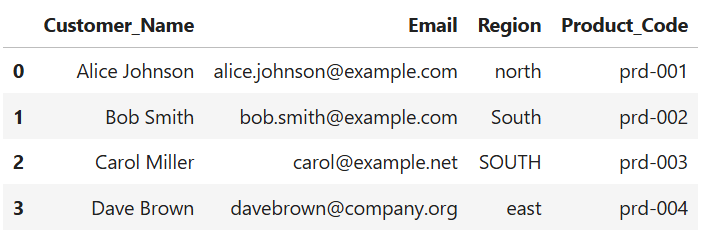
Let's imagine we have the following sample sales dataset:
import pandas as pd
data = {
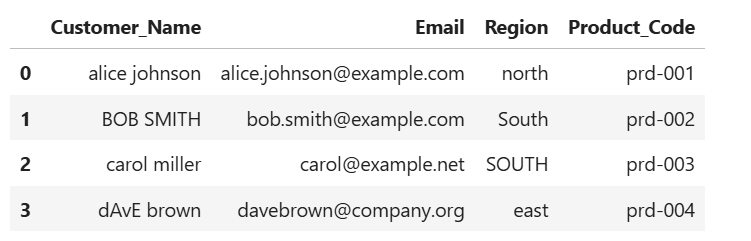
'Customer_Name': ['alice johnson', 'BOB SMITH', 'carol miller', 'dAvE brown'],
'Email': ['alice.johnson@example.com', 'bob.smith@example.com', 'carol@example.net', 'davebrown@company.org'],
'Region': ['north', 'South', 'SOUTH', 'east'],
'Product_Code': ['prd-001', 'prd-002', 'prd-003', 'prd-004']
}
df = pd.DataFrame(data)
print(df)


🛠️ String Handling Examples
1. Title Case Customer Names
Customers' names are inconsistently formatted. Let's fix that using .str.title():
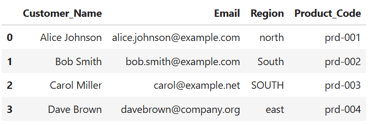
df['Customer_Name'] = df['Customer_Name'].str.title()
print(df)
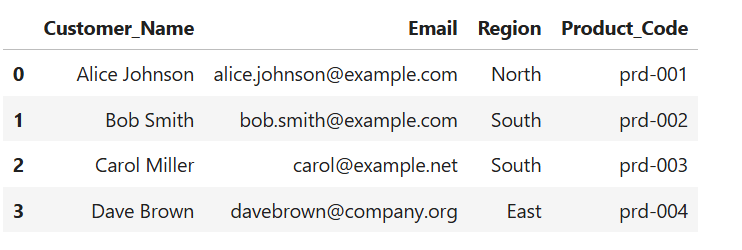
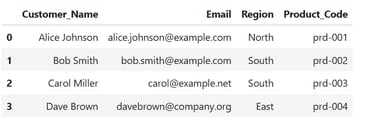
2. Standardize Regions
Regional data should be consistent for grouping and filtering. We'll convert them all to lowercase, then capitalize:
df['Region'] = df['Region'].str.lower().str.capitalize()
print(df)
3. Extract Email Domain
Want to see what email providers your customers use? Extract the domain using .str.extract():
df['Email_Domain'] = df['Email'].str.extract(r'@(.+)$')
df


4. Check for Specific Domain
Want to flag customers using company email addresses?
df['Is_Company_Email'] = df['Email'].str.contains('company.org')
df

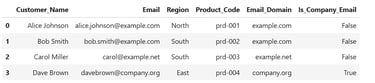
5. Split Product Code
Let’s break down the product code into prefix and ID:
df[['Product_Prefix', 'Product_ID']] = df['Product_Code'].str.split('-', expand=True)
print(df)
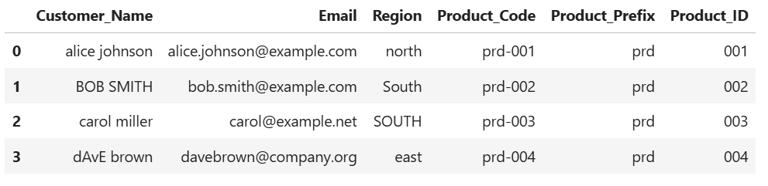

6. Remove Leading and Trailing Spaces
Sometimes, customer names or regions might contain accidental spaces that break matching:
df['Customer_Name'] = df['Customer_Name'].str.strip()
print(df)
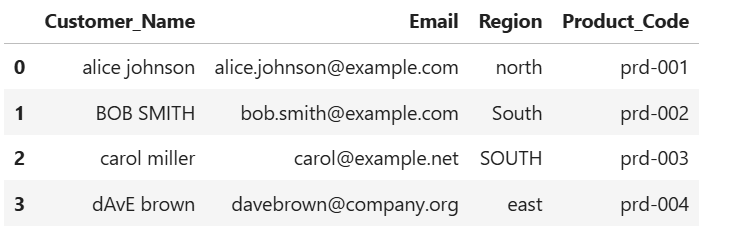
7. Find Customers from a Specific Region
Let’s filter all customers from the "South" region (case-insensitive):
south_customers = df[df['Region'].str.lower() == 'south']
#south_customers = df[df['Region'].str.contains('south', case=False)]
print(south_customers)


8. Find Duplicate Regions
You can group and count customers by email domain:
df['Region']=df['Region'].str.lower()
Region_counts = df['Region'].value_counts()
print(Region_counts)
Output:
Region
south 2
north 1
east 1
Name: count, dtype: int64
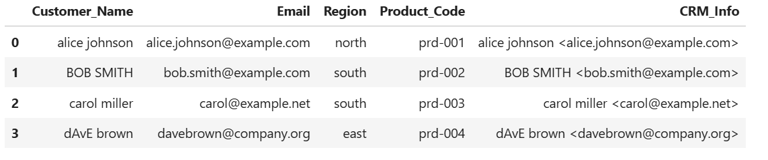
9. Concatenate Customer Info for CRM Export
Combine name and email for CRM system import:
df['CRM_Info'] = df['Customer_Name'] + ' <' + df['Email'] + '>'
print(df)
10. Filter Customers by Product Code Prefix
If you have multiple product categories like prd-, svc-, pkg-:
df[df['Product_Code'].str.startswith('prd-')]
df
11. Create URL Slugs from Customer Names
Generate SEO-friendly slugs for profiles or links:
df['Slug'] = df['Customer_Name'].str.lower().str.replace(' ', '-')
print(df)


12. Remove Special Characters in Names
To clean up extra characters (like for exporting to CSVs):
df['Customer_Name'] = df['Customer_Name'].str.replace(r'[^\w\s]', '', regex=True)
print(df)
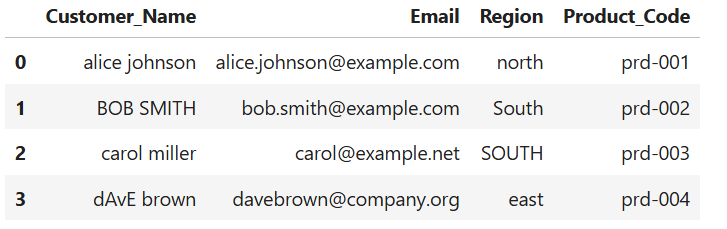

13. Pad Product IDs for Consistency
Ensure all product IDs are 5 digits (e.g., 00001, 00023):
df[['Product_Prefix', 'Product_ID']] = df['Product_Code'].str.split('-', expand=True)
df['Product_ID_Padded'] = df['Product_ID'].str.zfill(5)
print(df)
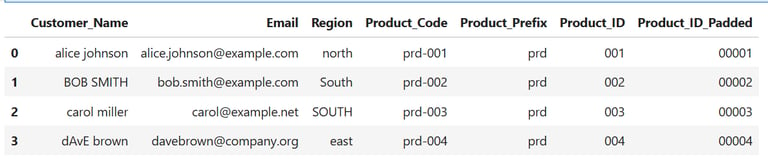
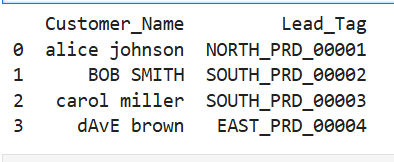
14.Combine Techniques for a Sales Pipeline
Example: Build a sales lead tag from multiple fields:
df['Lead_Tag'] = (
df['Region'].str.upper() + '_' +
df['Product_Prefix'].str.upper() + '_' +
df['Product_ID_Padded']
)
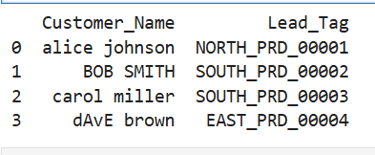
print(df[['Customer_Name','Lead_Tag']])
✅ Key Takeaways: String Handling in Sales Data with Python & Pandas
Text data is everywhere in sales — from customer names and emails to product codes and regions. Clean, consistent string data is essential for analysis and reporting.
Pandas .str functions offer powerful tools for:
Formatting (e.g., .str.title(), .str.upper())
Cleaning (e.g., .str.strip(), .str.replace())
Extracting patterns (e.g., .str.extract(), .str.contains())
Use string handling to:
Normalize inconsistent text (e.g., regions, product codes)
Extract meaningful information (e.g., email domains, prefixes)
Mask or validate sensitive data (e.g., email privacy, format checking)
Prepare data for exports, CRMs, or dashboards
Combining multiple string functions allows you to build custom tags, clean export fields, or segment customers more effectively.
Investing time in string cleaning pays off in:
Better data accuracy
Smoother data merges and joins
Clearer dashboards and reports

Kishore Babu Valluri
Senior Data Scientist | Freelance Consultant | AI/ML & GenAI Expert
With deep expertise in machine learning, artificial intelligence, and Generative AI, I work as a Senior Data Scientist, freelance consultant, and AI agent developer. I help businesses unlock value through intelligent automation, predictive modeling, and cutting-edge AI solutions.
Let's Get in Touch
marketing@deepaiautomation.com
+91 6309397994
© 2025. All rights reserved.
Industries
Manufacturing
Financial Services
Retail
Solutions
DocuMind AI - Intelligent Document Migration
InsightEdge AI - Intelligent Power BI Reporting & Analytics
DCT AI - Digital Control Tower for Intelligent Enterprise Visibility
Inventra AI - Intelligent Inventory Optimization Platform
Maintenix AI - Predictive Maintenance Intelligence Platform
PayPredict AI - Intelligent Customer Payment Prediction Platform
SegMind AI - Intelligent Customer Segmentation & RFM Analytics Platform
DataForge AI - Intelligent ETL & Analytics Modernization Platform
DataSense AI - Intelligent Data Quality & Outlier Detection Agent